一文爆肝stable diffusion绘画底层原理

当你打开这篇文章的时候,我猜你对stable diffusion是有浓厚的兴趣的,应该很想学会它!你也肯定知道输入提示词就能让SD绘制出优美的图片,但你也许会被模型、clip、latent space、u-net以及vae等概念搞得摸不着头脑,那么这篇文章必定适合你,可以让你快速了解SD的底层绘画逻辑~
👉获取更多资料,可以加我微信进群获取:

文章主要分3点进行讲解
- 图片和稳定扩散
- 模型是如何训练的
- SD绘画背后原理
图片和稳定扩散
- 传统图像生成的算力困局
图片有三个通道,举个数学例子:
一张512×512的RGB图像包含786,432个参数(512×512×3),计算机渲染它相当于处理784页A4纸填满数字的数学题。
若直接在像素空间训练扩散模型,单个注意力层的计算量达到O(512²×512²)=O(68,719,476,736),这导致:
1.B显存GPU无法承载1080P图像生成
2.理耗时超3分钟(RTX 3090实测)
- 稳定扩散的破局关键:潜在空间(Latent Space)
潜在空间通过 变分自编码器(VAE) 将高维像素数据压缩至低维(如64×64×4),数据量减少97.9%(786,432→16,384),使扩散模型在保留图像语义特征的前提下,计算复杂度降低4096倍。
这一设计突破使生成高清图像的内存占用减少64倍、推理速度提升25倍(如RTX3090生成512px图像从180秒降至7秒),从而解决了像素空间直接建模的算力瓶颈与感知失真问题。
模型的训练
在模型的世界里,图片并不是以我们所理解的色彩形式存在,而是一堆数字形式的数据。
模型训练的过程主要有几个步骤:
-
通过变分自编码器(VAE,包含
Encoder与Decoder,压缩对应Encoder)将高维的图片数据压缩到一个低维的潜在空间(它是一个连续的向量空间,模型在这个空间中进行操作,而不是直接在像素空间中进行操作)。这个潜在空间的数据量通常比原始图片小得多(如64×64×4),这样可以减少计算量。 -
逐步向图片添加噪声(这是一个前向扩散过程)。形象一点描述:在一块草坪上逐步撒上花瓣,直到花瓣铺满草坪。

-
指定底模(Base Model),底模通常是预训练的,已经学习了一定的图像分布(它不仅可以约束图像的风格,还能提供模型的基础生成能力)。
-
给定的提示词通过文本编码器(如CLIP)被转换为文本嵌入(Text Embedding),然后将这些Text Embedding与图片的潜在空间进行结合,指导生成过程(即如何降噪,说人话就是逐步将花瓣去除,直到恢复出草坪的原貌)。真实的降噪过程如下图:

简单总结一下训练过程:
通过训练模型理解"噪点如何一步步覆盖真实图片",再反向操作,从噪点中重建符合描述的图像。提示词和底模型的作用是引导去噪方向,确保最终结果和你想要的匹配。
当然,训练过程并不是一张图就能完成的,需要大量的图片和对应的文本描述进行训练,以便模型学习文本与图像之间的对应关系~
SD绘画背后原理
SD绘图的操作流程相对来说是固定的:
选择固定风格的模型->输入正反向提示词->设置控制条件->点击生成图片,即可生成图片。
如果我们掀开SD这层表皮,它的真实绘制步骤大概是这样的:
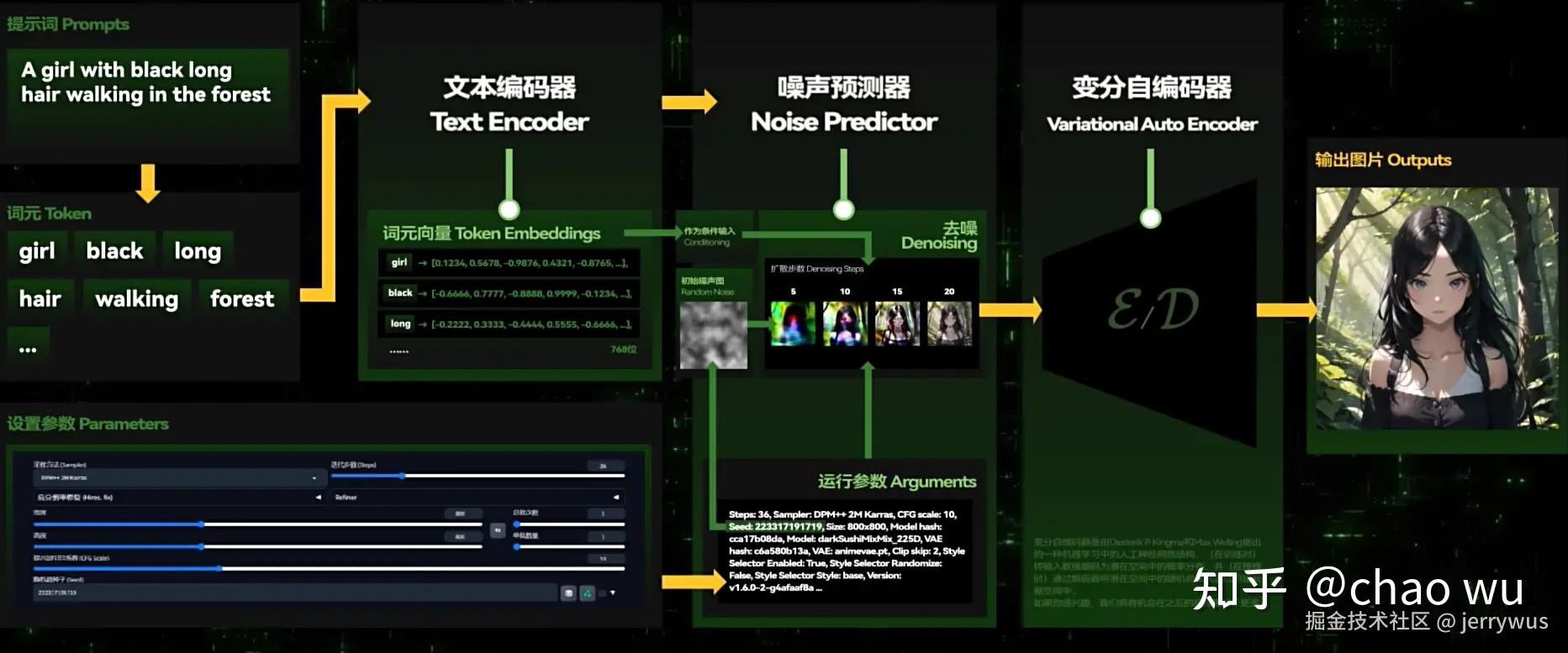
文本编码
我们输入一段提示词,比如“一个黑色长发女孩走在森林中”,这段文字其实是自然语言,模型是无法直接理解的。模型会用一个文本编码器(CLIP)把你的提示词转换成"向量表示"(一串数字密码),这个密码代表了文字的核心含义和特征。中向量可以理解为资源位置(类似于坐标),它们通过一定的方式加总在一起,就得到了我们绘制一张图片所需的规律(后续可以指导降噪生成过程)。

潜在空间初始化
初始化潜在空间,并在潜在空间中根据设定的采样器,采样步数,图片尺寸生成一个随机噪声图像(这张噪点图没有任何意义,但它是后续加工的"原材料),这个图像在初始阶段是纯噪声。大概长这样:

噪声预测(Noise Predictor)
然后噪声预测器会根据文本编码器(之前生成的词元向量)的指导下反复猜测当前噪点图中的多余噪点,然后一点点擦除噪点,逐渐露出清晰的图案,并为图片增加一些关键信息,再经过若干次循环迭代后,大概的形象就会绘制完成。
VAE图像解码
但此时图片还存在于潜在空间里,还是计算机才能够理解的向量数据。
最后再通过VAE(变分自解码器)解码就可以将向量数据转换为我们人类可以看懂的图片了。
一张图总结
关于采样器的介绍
请看:https://www.bilibili.com/video/BV1FN411i7sB/
整合包模型资源分享
整合包下载地址
模型资源分享
插件资源
4x-UltraSharp 放大算法
秋叶炼丹炉整合包
👉获取更多资料,可以加我微信进群获取: